
<blockquote> 编者按: 我们今天为大家带来的文章,作者的观点是:GPU 工程的核心不在于手写内核的能力,而在于构建系统设计思维 —— 理解从模型定义到硬件层的完整技术栈如何协同工作。
作者提出了一个五层渐进式调试框架:从模型定义(Model Definition)入手,识别计算与内存瓶颈;进入并行化(Parallelization)阶段,解决多卡同步问题;深入运行时编排(Runtime Orchestration),优化集群资源利用率;通过编译与优化(Compilation & Optimization)提升生产环境性能;最终触及硬件层的物理极限。文章阐释了每一层级的典型瓶颈与解决思路,强调 80% 的问题可通过前三层的系统设计解决,内核工程仅在边缘场景中才真正发挥作用。
作者 | Abi Aryan
编译 | 岳扬
最近有条推文在 X 平台爆火——
大多数人看到后的想法是:我得学会 CUDA 内核开发才能体现自身价值。
但事实并非如此。
即便投入毕生精力,你大概率也挤不进那个百人左右的精英圈子。
内核开发固然重要,但不应作为入门起点。首要的是理解整个系统应该如何协同运作。
你或许读过无数关于 Triton 内核、将 PCIe 与 NVLink 进行对比、或是 DeepSpeed ZeRO 的帖子,但作为 GPU 工程师,真正的核心问题不是”我能手写内核吗”,而是”这些模块如何衔接?何时需要关注哪个环节?”因为行业真正的短板并非工具使用能力,而是系统设计能力。
极少有人能真正将模型视为硬件中流动的字节,将张量看作内存中的布局排列 —— 这正是内核工程师的思维境界。但若想进入这个精英群体,你首先得理解一切是如何映射的。
今天这篇文章,我就来帮你建立这种系统设计的认知框架。
当你的模型分布在几十甚至上百块 GPU 上时,你问的就不再只是”我的代码对不对?”,而是”我的 GPU 们是否高效协同工作,还是在互相拖后腿?”
真正的瓶颈往往出现在同步、通信、调度和资源利用率上。
为了理解这一点,我们先退一步,看看所有模型都会经历的系统工作流程(从左向右):
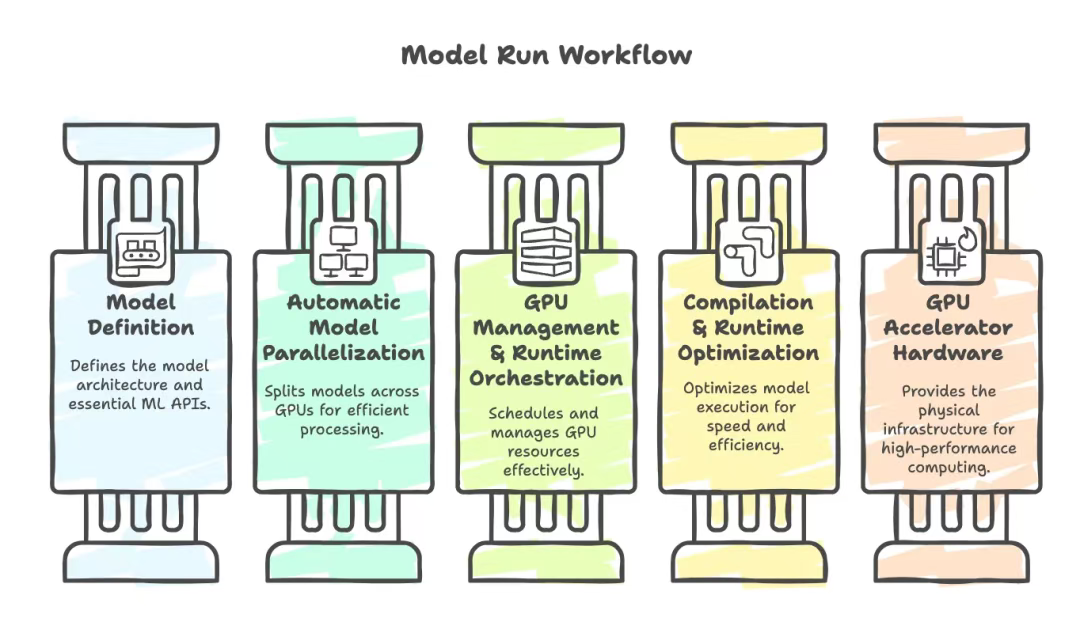
我们总是从模型定义层(Model Definition)入手。这一步更快速、更简单,且杠杆效应更高。只有当你无法在此层解决问题时,才需要逐级深入后续环节。
01 第一层:模型定义(Model Definition)
这是大多数机器学习工程师起步并投入最多时间的地方:定义 Transformer 层、将其接入 PyTorch、依赖自动微分系统,并将一系列张量运算串联起来。

这一阶段出现问题,通常源于:
- 稠密矩阵乘法受计算限制,使 GPU 算术逻辑单元达到或接近最大工作负荷。
- 注意力层受内存带宽制约,卡在等待数据传输,而非计算本身。
- 启动了过多的小型计算内核,导致调度开销过大。
在这一阶段调试,意味着使用 PyTorch 或 JAX 工具进行性能分析,并思考: “这属于计算问题、内存问题,还是框架效率问题?”
现在让我们看个实例——
当你的大语言模型规模暴增时,限制训练速度的不只是计算能力,更关键的是内存带宽。
当 GPT 这类模型的参数规模变得极其庞大时,限制训练速度的主要因素不再是 GPU 的计算能力,而是数据搬运的速度(即内存带宽)。特别是在计算自注意力机制中的 Q(查询)、K(键)、V(值)矩阵时,需要频繁地在显存中存取海量数据,这个”搬运数据”的过程成为了整个系统的瓶颈。解决方案是什么?FlashAttention —— 一种通过重新组织计算顺序来减少内存延迟的融合核函数。若不理解系统原理,你根本无法解释 GPU 为何处于闲置状态。
你的职责是确保模型运行,尝试优化,继而进行调试。
掌握每层对应的工具和框架,能帮你解决 80% 的问题,kernel engineering 则能帮你榨取剩下的 20%。但若妄想绕过基础直接攻克那 20%,很遗憾,我的结论依然成立。
即便投入毕生精力,你大概率也挤不进那个百人左右的精英圈子。
在调试过程中,你会循着下图所示的层级链条,依次逐层深入排查问题。
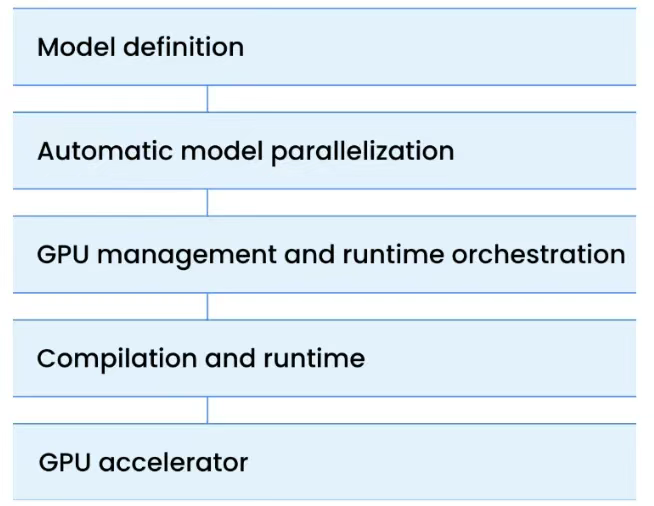
请将 GPU 协同调度工作想象成楼梯。每一级台阶都对应技术栈中的不同层级,每层都对应着独特的性能瓶颈与故障模式。只要某一层没处理好,整体性能就会下降。请从最顶层开始,仅在必要时才向下深入。
接下来,让我们看向下一层级——
02 第二层:并行化(Parallelization)
假设单块 GPU 已无法满足你的大语言模型(LLM)训练需求——这几乎是常态。于是你开始横向扩展,这时你就进入了并行化(Parallelization)阶段。这时,核心挑战往往不再是单卡的计算能力,而是多卡间的同步问题:梯度必须在 GPU 之间流动,模型参数需要分片,优化器状态也得拆分。

在这一层,瓶颈通常来自于:
- 同步式全规约核函数因少数几个速度慢的 GPU 而陷入等待。
- PCIe 或 NVLink 带宽限制,或是
- 异步更新虽提升了吞吐量,却可能引入过时梯度(stale gradients)的风险。
到了这一层,你的核心问题就从”我的计算内核是否高效?”转变为”我的 GPU 集群是否在高效交换信息?” 。DeepSpeed ZeRO 能帮助你对状态和梯度进行分片,但同时也会引入通信开销。
此时,瓶颈不再是 GPU 计算核心,而是网络互联架构(network fabric)。你需要在强同步(稳定但较慢)和宽松的异步更新(更快但有风险)之间做权衡。
如果性能分析显示通信与计算的重叠程度不佳,或许可采用融合核函数(fused kernels)或自定义核函数来降低传输期间的计算开销,但这类情况较为罕见,通常 DeepSpeed ZeRO 或 Megatron-LM 已经内置了这类优化。
接下来我们继续深入下一层级——
03 第三层:运行时编排(Runtime Orchestration)
当你从单一模型训练任务扩展到大规模任务集群时,就进入了运行时编排(Runtime Orchestration)阶段。此时,你不再纠结于”我的注意力核函数高效吗?”,转而追问:”为什么我有 30% 的 GPU 处于空闲状态?”

在这一层,问题通常表现为:
- 半数 GPU 因某个计算节点延迟而集体闲置。
- 因调度策略不公导致任务在队列中阻塞。
- 大量零散小任务导致资源碎片化,造成集群资源浪费。
在此层级调试,意味着你要问: “我是否有效地编排了资源,让 GPU 把时间花在训练上,而不是等待上?”
来看一个例子 —— 我们在演讲中讨论过的 DeepMind 案例:

TLDR:DeepMind 报告称,即使拥有数千块 GPU,分布式训练仍会卡顿,因为少数慢节点拖慢了全局同步。在数据并行训练中,整个任务必须等待最慢的那个工作节点。Ray 和 Kubernetes 通过弹性管理(节点故障时重新分配任务)和调度优化(避免 GPU 在队列中闲置)来缓解这类问题。
但编排系统无法凭空修复糟糕的同步逻辑——你必须同时调优编排策略和并行化设计。
一旦这些基础工作到位,你才可能去写融合核函数(fused kernels),或是优化集合通信核函数(比如自定义的 all-reduce 实现),以略微减少 GPU 在等待通信时的计算空窗期;或者预取张量、对齐数据来适配 DMA 传输;又或者实现能感知调度的自定义核函数,在 Ray/Kubernetes 等编排器调度任务的同时,更充分地利用 GPU 流水线。
但再次强调:kernel engineering 仅适用于边缘场景,且是否需要它,完全取决于调试过程中遇到的具体问题类型。
04 第四层:编译与优化 (Compilation & Optimization)
训练完成后,大语言模型(LLMs)需要服务数百万请求,此时你关注的是生产环境中的延迟(latency)和吞吐量(throughput)。在这个阶段,每一毫秒都至关重要。编译器通过融合核函数、优化数据在内存中的存放和访问方式以及降低精度等方式来解决这些问题。

因此,该层级的主要挑战在于:
- 过多小型操作导致的核函数启动开销。
- 程序运行时间主要被内存数据传输所占据(例如嵌入向量查询)。
- 缺乏融合或量化技术导致性能潜力未被释放。
此时的瓶颈已不再是训练速度,而是在真实流量下的吞吐量与延迟表现。在此层级调试,意味着你要对推理负载进行性能分析,并思考: “我是否在每一块 GPU 算力上榨取了最大吞吐收益?”
以 ChatGPT 推理为例:其推理过程通常涉及大量小型操作(即逐 token 生成)。如果每个操作都单独启动一个核函数,那么核函数启动开销就会成为性能瓶颈。
像 TorchInductor 这样的编译器会将多个操作融合成更大的核函数,而 TensorRT 则通过将模型量化为 FP16 或 INT8 来节省计算和内存开销。随后,Triton Server 对多个推理请求进行动态批处理(batching),从而让 GPU 能够高效地同时处理成千上万的请求。
正是在这一层,kernel engineering 才真正变得重要。与 Layer 1–3 不同,Layer 4 是手写调优或编译器级干预能显著影响延迟和吞吐的阶段。不过,通常只有在现有编译器能力已被充分挖掘之后,你才会考虑编写自定义核函数。自定义核函数适用于那些在单次推理或训练步骤中被调用数百万甚至数十亿次的高频率操作。
因此,核心要旨在于——
Layers 1–3:聚焦系统设计、资源编排与并行化策略,核函数编写在此层面基本无关紧要。
Layer 4:运用编译器优化、批处理、量化与融合技术,大多数现实场景的瓶颈在此即可解决。
而定制核函数仅当性能分析证实现有优化仍不足,且存在值得手工调优的高杠杆操作时才能真正派上用场。
05 第五层:硬件层
这是整个系统的基石。所有核函数、同步操作与分片策略,最终都受限于 GPU 及互联硬件的物理极限。

这一层级的瓶颈表现为:
- 模型并行时达到 NVLink 带宽上限。
- 跨节点扩展时 PCIe 成为性能瓶颈。
- GPU 显存容量不足,被迫将数据卸载(offload)到 NVMe 存储。
这些问题无法通过框架层面的优化来”修复”。你只能通过重构工作负载、降低精度(如使用 FP16/INT8),或直接升级硬件来规避。
在大规模训练中,当数千块 GPU 同步梯度时,InfiniBand 网络链路常常会被打满。这种瓶颈无法靠写代码绕过去——PCIe 和 NVLink 的带宽是有限的。也正是在这里,AI 工程开始与硬件工程深度融合。
唯一的解决方案来自架构层面:采用更先进的互联技术、降低同步频率,或重新设计算法以减少通信量。
此处引入我们讨论过的另一个案例研究——
Spectrum X 能够分析 GPU 显存使用率、互联带宽(NVLink/PCIe/InfiniBand)及核函数执行情况,精准定位瓶颈所在。
06 The Key Lesson
每一层都是模块化的,但又相互依赖:
- 如果在模型定义层(Model Definition)内存管理不当,就会在并行化层(Parallelization)引发通信瓶颈。
- 如果在并行化层(Parallelization)同步配置错误,就会导致运行时编排层(Runtime Orchestration)GPU 大量闲置。
- 如果在编译层(Compilation)忽视核函数融合(kernel fusion),就会在生产环境中因延迟过高而白白烧钱。
因此,当你的模型:
受计算限制(Compute-bound) → 通过模型或核函数优化来解决。
受内存限制(Memory-bound) → 通过分片(sharding)、重计算(recomputation)和核函数融合来缓解。
受通信限制(Communication-bound) → 依靠并行化(parallelization)和运行时编排(orchestration)来应对。
一旦你掌握了这张系统地图,那些零散的博客文章、论文和争论就不再杂乱无章 —— 它们会立刻各归其位,成为整个大系统中清晰可辨的组成部分。
END
本期互动内容 🍻
❓你在训练或推理中遇到的性能瓶颈,更多来自计算、内存,还是通信?是怎么发现的?
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://modelcraft.substack.com/p/fundamentals-of-gpu-engineering
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


